Die gefährlichste Illusion in der aktuellen Sicherheitsdebatte ist nicht, dass KI überschätzt wird. Die gefährlichste Illusion ist, dass wir noch Zeit hätten.
Diese Zeit verschwindet gerade. Nicht, weil irgendwo ein mythisches Supermodell vom Himmel gefallen wäre, sondern weil die technische Kette zwischen Patch, Analyse, Exploit und Massenangriff immer kürzer wird. Und weil viele Verteidigungsprozesse noch immer so tun, als sei ein monatlicher Patchlauf eine ernsthafte Antwort auf maschinenbeschleunigte Angriffe.
Wer das als Panikmache mit geheimen Frontier-Modellen abtun will, macht es sich inzwischen zu leicht. Der relevante Punkt ist nicht mehr nur, dass ein einzelner Anbieter ein spektakuläres Showcase gebaut hat. Relevanter ist, dass dieselbe Richtung offenbar auch mit billigeren, kleineren und offeneren Modellen funktioniert. Im VentureBeat-Artikel zu Mythos, Detection Ceiling und dem Defender-Playbook wird AISLE mit einem ziemlich unangenehmen Befund zitiert: Die Forschenden hätten Anthropics Showcase-Fälle mit kleinen Open-Weights-Modellen gegengeprüft; acht von acht hätten den FreeBSD-Fall erkannt, ein Modell mit 3,6 Milliarden Parametern soll bei rund 11 Cent pro Million Tokens liegen, und ein offenes 5,1B-Modell habe die Kernanalyse des alten OpenBSD-Bugs reproduziert.
Der wichtigste Satz daran ist nicht das Benchmark-Geklapper, sondern die Schlussfolgerung: „The moat in AI cybersecurity is the system, not the model.“
Wenn das stimmt, ist die Lage ziemlich nüchtern: Das hier ist keine exklusive Laborzauberei mehr. Es ist eine Fähigkeit, die über Workflows, Tooling, Auswerteschleifen und billigere Modelle in die Breite diffundiert. Nicht nur die Offence wird besser. Sie wird auch günstiger. Und das ist für die Verteidigung die eigentlich schlechte Nachricht.
Patch raus, Angriff läuft
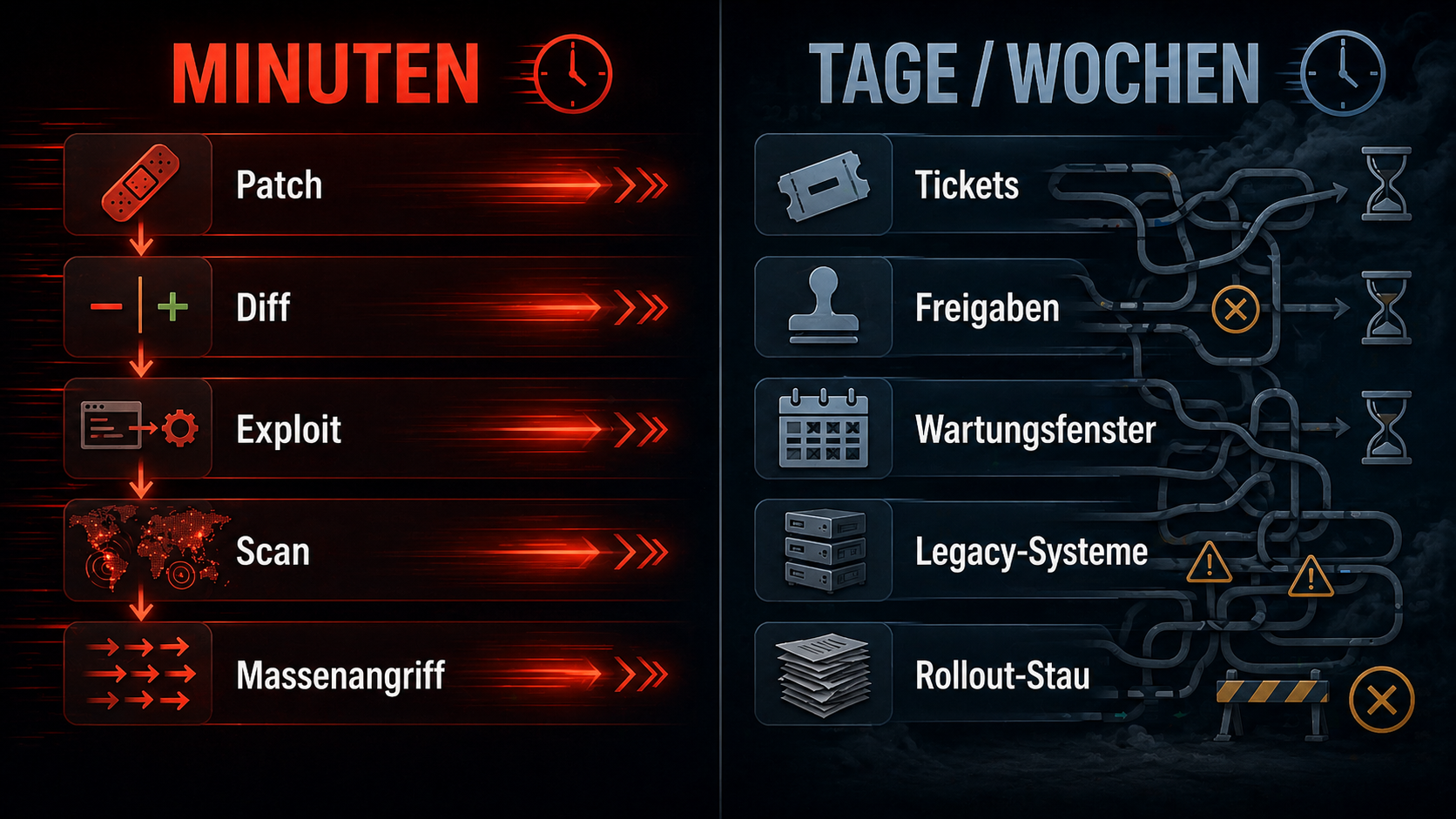
Die Angriffskette ist heute unangenehm kurz: Ein Patch erscheint. Der Diff verrät die Stelle. Daraus wird die Schwachstelle rekonstruiert. Dann wird geprüft, ob sich das waffenfähig machen lässt. Danach sucht man nach betroffenen Systemen, idealerweise automatisiert und im Zweifel über Shodan gleich mit. Und dann läuft der Massenangriff.
Nicht irgendwann. Nicht nach langer romantischer Handarbeit. Sondern so schnell, wie Analyse, Zielsuche und Exploitbau automatisierbar sind. Genau hier wird KI praktisch gefährlich: nicht als Science-Fiction, sondern als Beschleuniger einer ohnehin schon bekannten N-Day-Kette.
Ein veröffentlichter Patch ist damit oft nicht nur die Reparatur, sondern gleichzeitig die technische Gebrauchsanweisung für den nächsten Exploit. Das ist keine neue Idee. Neu ist die Geschwindigkeit, mit der sich diese Gebrauchsanweisung auswerten, mit Assets korrelieren und in Angriffspfade übersetzen lässt.
Die Verteidigungskette ist Verwaltung
Auf der Verteidigungsseite beginnt nach einem Patchrelease erst einmal die übliche Prozession der Langsamkeit: Die Information muss ankommen. Jemand muss verstehen, dass sie relevant ist. Betroffene Produkte und Systeme müssen identifiziert werden. Zuständigkeiten müssen geklärt werden. Ein Wartungsfenster muss her. Dann wird getestet. Dann ausgerollt. Danach hofft man, dass wirklich alles getroffen wurde und nicht irgendwo noch eine vergessene VM, ein altes Appliance-Image oder ein halbtotes Legacy-System offen herumsteht.
Das ist der operative Skandal. Angreifer brauchen einen funktionierenden Pfad. Verteidiger brauchen funktionierende Organisation. Die eine Seite arbeitet mit maschinenfreundlichen Ketten. Die andere mit Meetingketten. Und Meetingketten gewinnen gegen maschinenfreundliche Angriffspfade ungefähr so zuverlässig wie ein Faxgerät gegen eine API.
Wer reale Patchzyklen kennt, weiß, wie hässlich diese Wahrheit ist: Wochen sind normal. Monate sind keine Seltenheit. Manche kritischen Lücken verschwinden selbst dann nicht sauber aus der Fläche, wenn seit Ewigkeiten bekannt ist, dass sie aktiv missbraucht werden. Log4Shell war deshalb kein einmaliger Schock, sondern ein Lehrstück. Nicht, weil der Bug so exotisch gewesen wäre, sondern weil so viele Umgebungen gezeigt haben, wie langsam Erkenntnis, Verantwortung und Ausrollung tatsächlich zusammenfinden.
DevSecOps hat die Lücke nicht geschlossen
Es wäre bequem, jetzt einfach auf DevOps und DevSecOps zu zeigen. Dafür haben wir das doch, oder?
Nur stimmt das in der Praxis zu oft nicht. Ja, diese Ansätze haben Builds, Pipelines, Artefaktflüsse und Scanner verbessert. Sie haben auch geholfen, Sicherheitsprüfungen früher in Entwicklungsprozesse zu schieben. Das ist nicht wertlos. Aber sie haben vielerorts nicht dafür gesorgt, dass aus einem akut relevanten Patch schnell eine belastbare operative Reaktion wird.
Zu oft wurde nur die Verwaltung des Bestehenden hübscher, nicht aber die Reaktionsgeschwindigkeit wirklich hart beschleunigt. Wenn ein Unternehmen noch immer im Monatsrhythmus auf Updates schaut, Hinweise manuell sortiert, betroffene Systeme nur über Bauchgefühl kennt und Priorität über Tickets statt über reale Exposition herstellt, dann ist das kein Sicherheitsprozess. Das ist geordnete Langsamkeit mit Compliance-Beleuchtung.
AIOps ist nicht Kür, sondern Ausweg
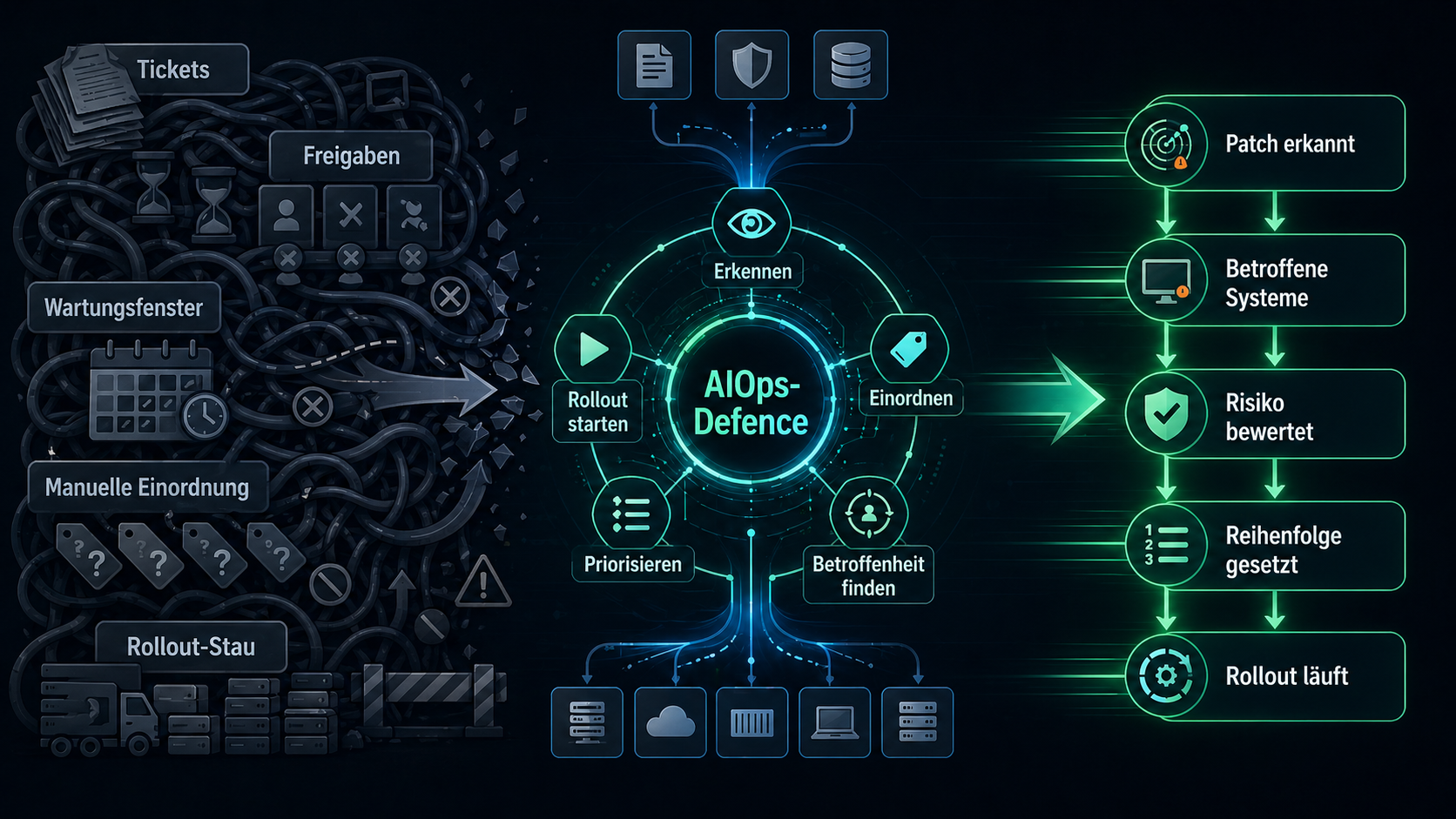
Wenn die Angriffskette maschinell beschleunigt wird, muss die Verteidigungskette ebenfalls maschinell beschleunigt werden. Nicht als Chatbot-Demo. Nicht als bunter KI-Sticker auf altem Ticketing. Sondern als echter Prozessbeschleuniger.
Genau hier wird AIOps sicherheitsrelevant: Da ist ein neuer Patch. Der ist dringend, weil aus Advisory und Diff sehr wahrscheinlich genau diese Schwachstelle hervorgeht. Diese Hosts, Images, Cluster, Appliances und Gerätegruppen sind betroffen. Diese Systeme sind internetnah. Diese davon stehen in kritischen Pfaden. Diese Updates fehlen noch. Diese Reihenfolge minimiert Risiko und Zeitverlust.
Das ist keine Magie. Es ist Arbeit, die Maschinen besser vorbereiten können als Menschen, wenn die Daten halbwegs vorhanden sind: Advisorys lesen, Diffs einordnen, Assets korrelieren, Exploitability und Exposition gewichten, Rollout-Prioritäten ableiten und nachhalten, wo die Maßnahme noch fehlt. Nicht einmal im Monat auf „Update verfügbar“ klicken, sondern innerhalb sehr kurzer Zeit wissen: Da ist ein Patch. Der ist dringend. Diese Systeme sind betroffen. Hier müsst ihr zuerst hin.
Wie so etwas in kleiner, kontrollierter Form bereits praktisch aussehen kann, zeigt auch der frühe Infrastruktur-Artikel „Sie hat’s schon wieder getan“ – Steffi nimmt einen Dedicated Server in Betrieb (mit Sicherheitsgurt): Dort geht es zwar noch nicht um automatisierte Patch-Priorisierung im großen Stil, aber sehr wohl um denselben Kern — sauber geführte, beschleunigte Ops unter klaren Leitplanken statt hektischer Handarbeit im Web-UI. Genau in diese Richtung muss Security-Betrieb weitergezogen werden, nur deutlich härter auf Patch-Erkennung, Betroffenheitsanalyse und Rollout-Geschwindigkeit.
Die schlechte Nachricht ist die Skalierung
Man muss daraus keine Apokalypse bauen. Aber man sollte endlich aufhören, es für beruhigend zu halten, dass nicht jede Angriffsfähigkeit aus einem geheimen Spitzenmodell kommt. Gerade das Gegenteil ist das Problem.
Wenn auch kleinere, billigere Modelle in brauchbaren Systemen denselben Pfad unterstützen, wird die Lage nicht entspannter, sondern breiter, billiger und schneller. Die Bedrohung steigt also nicht nur, weil einzelne Frontier-Modelle beeindruckender werden. Sie steigt, weil die Fähigkeit diffundiert und weil die Angriffskette deutlich besser skaliert als die organisatorische Gegenreaktion.
Solange Verteidiger diesen Geschwindigkeitsnachteil nicht technisch auffangen, bleibt Patchmanagement vielerorts nur ein freundlicherer Ausdruck für zu späte Reaktion. Prozesse, die auf menschliche Weiterleitung, manuelle Einordnung und träge Rollout-Zyklen angewiesen bleiben, sind für diese Bedrohungslage schlicht zu langsam.